
Installer une IA / LLM sur son propre ordinateur, c'est facile : le guide complet pour tous les niveaux

- Tilo
- Modifié le
Partager la publication
Vous rêvez d'avoir votre propre assistant IA personnel qui fonctionne directement sur votre ordinateur, sans limites et en toute confidentialité ? Bonne nouvelle : installer un grand modèle de langage (LLM) chez soi n'est plus réservé aux experts ! En 2025, cette technologie est devenue accessible à tous. Suivez notre guide détaillé pour transformer votre PC ou Mac en centre de commande IA privé.
Pourquoi choisir une IA locale plutôt que ChatGPT ?
L'installation d'un LLM local présente des avantages considérables que même les géants du cloud ne peuvent égaler. Contrairement aux services en ligne, votre IA personnelle vous offre une confidentialité absolue : aucune de vos conversations ne quitte votre machine. Fini les inquiétudes sur l'utilisation de vos données !
L'autonomie totale représente un autre atout majeur. Votre assistant IA fonctionne même sans connexion Internet, idéal lors de vos déplacements ou en cas de panne réseau. Plus de limites d'utilisation, de quotas ou d'abonnements mensuels - votre IA est disponible 24h/24 sans restriction.
La personnalisation poussée devient possible : vous pouvez adapter votre modèle à vos besoins spécifiques, créer des spécialisations sur mesure, et même entraîner l'IA sur vos propres données. Cette flexibilité inégalée ouvre des possibilités créatives infinies.
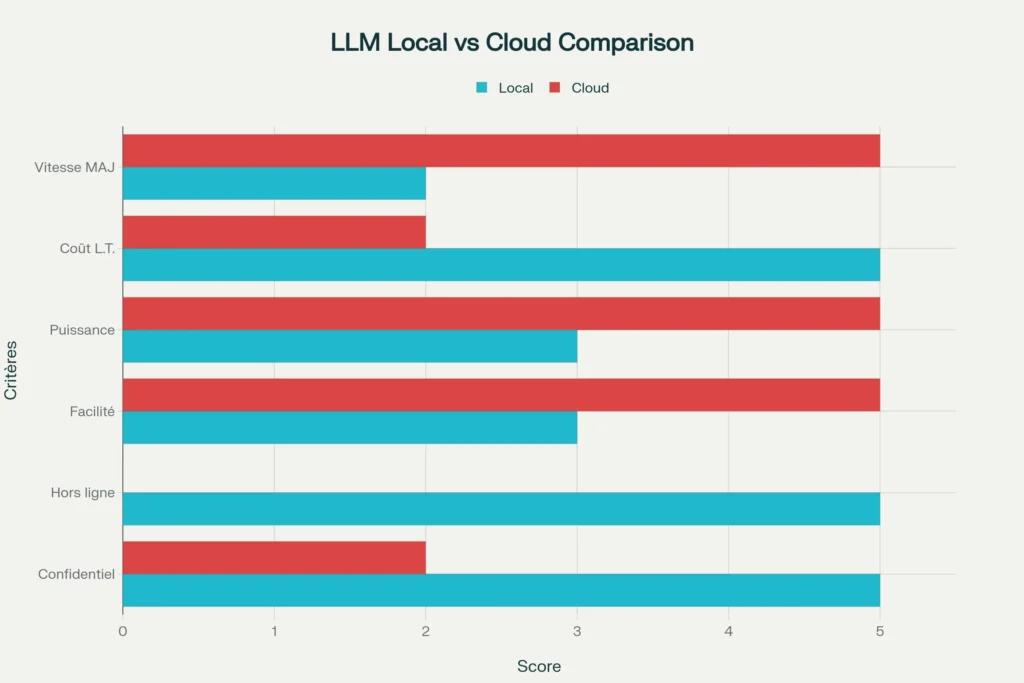
Enfin, l'aspect économique n'est pas négligeable. Après l'investissement initial en matériel, votre IA locale ne génère aucun coût supplémentaire, contrairement aux abonnements cloud qui s'accumulent mois après mois.
Le matériel nécessaire : de la configuration basique au PC de rêve
Configuration minimum (budget serré)
Pour débuter dans l'univers des LLM locaux, voici le strict minimum :
- Processeur : Intel i5 génération 8 ou AMD Ryzen 5 (post-2018)
- Mémoire vive : 8 Go de RAM (16 Go fortement recommandés)
- Stockage : 20 Go d'espace libre sur SSD
- Système : Windows 10/11, macOS 13+, ou Linux récent
Avec cette configuration, vous pourrez faire tourner des modèles légers comme TinyLlama ou Phi-3 Mini.
Configuration recommandée (usage régulier)
Pour une expérience confortable avec des modèles performants :
- Processeur : Intel i7 ou AMD Ryzen 7 récent
- Mémoire vive : 32 Go de RAM
- Carte graphique : NVIDIA RTX 3060 ou supérieure (8+ Go VRAM)
- Stockage : SSD NVMe avec 100 Go libres
Cette configuration permet d'utiliser des modèles puissants comme Mistral Small 3 ou Llama 3.2 avec fluidité.
Configuration de rêve (performances maximales)
Pour les utilisateurs les plus exigeants :
- Processeur : Intel i9 ou AMD Ryzen 9/Threadripper
- Mémoire vive : 64 Go de RAM ou plus
- Carte graphique : NVIDIA RTX 4090 ou RTX A6000 (24+ Go VRAM)
- Stockage : SSD NVMe 2+ To
Avec un tel setup, vous pouvez faire tourner les modèles les plus sophistiqués comme DeepSeek V2 ou Llama 3.1 70B.
Choisir le bon modèle pour votre configuration
Le choix du modèle détermine largement votre expérience. Voici nos recommandations basées sur des tests approfondis :
Modèles ultra-légers (moins de 2 Go)
TinyLlama 1.1B (0.6 Go) : Parfait pour les premiers tests sur des configurations modestes. Bien qu'il ne rivalise pas avec les gros modèles, il offre une excellente introduction aux LLM locaux.
Phi-3 Mini 3.8B (2.2 Go) : Le champion des petits modèles. Développé par Microsoft, il offre des performances étonnantes malgré sa taille réduite. Idéal pour les ordinateurs portables standard.
Modèles moyens (2-8 Go)
Mistral Small 3 (4.1 Go) : Notre recommandation principale pour débuter. Ce modèle français excelle en français et offre un excellent rapport performance/ressources. Compatible avec la plupart des configurations modernes.
Llama 3.2 8B (4.7 Go) : Le polyvalent de Meta. Excellent pour la conversation générale, la rédaction et l'analyse de texte. Support multilingue solide.
DeepSeek Coder 6.7B (3.8 Go) : Spécialement conçu pour la programmation. Si vous développez du code, ce modèle vous fera gagner un temps précieux avec ses suggestions ultra-précises.
Modèles lourds (plus de 10 Go)
Mistral Medium 22B (12.9 Go) : Pour ceux qui recherchent des capacités de raisonnement avancées. Excellent en français avec une compréhension contextuelle impressionnante.
Llama 3.1 70B quantifié (39 Go) : La Rolls-Royce des modèles open source. Performances quasi-équivalentes à GPT-4 mais nécessite un matériel puissant.
Guide d'installation pas-à-pas avec LM Studio
LM Studio reste l'outil le plus accessible pour installer facilement un LLM. Voici le processus détaillé :
Étape 1 : Téléchargement et installation (5 minutes)
- Rendez-vous sur lmstudio.ai depuis votre navigateur
- Cliquez sur "Download" et sélectionnez votre système d'exploitation
- Exécutez l'installateur téléchargé en tant qu'administrateur
- Suivez l'assistant d'installation en acceptant les paramètres par défaut
- Lancez LM Studio une fois l'installation terminée
L'interface s'ouvre avec un design épuré et moderne, similaire à ChatGPT.
Étape 2 : Exploration et téléchargement d'un modèle (15-45 minutes)
- Cliquez sur "Browse & Download Models" dans le menu principal
- Explorez le catalogue : plus de 1000 modèles sont disponibles
- Utilisez la barre de recherche pour trouver "Mistral Small 3" ou "Llama 3.2"
- Analysez les variantes : choisissez une version "Q4_K_M" pour un bon équilibre
- Cliquez sur "Download" et patientez (la vitesse dépend de votre connexion)
Un indicateur de progression vous tient informé du téléchargement. Pour un modèle de 4 Go, comptez 10-30 minutes selon votre débit.
Étape 3 : Configuration et premier lancement (2 minutes)
- Accédez à l'onglet "Chat" depuis le menu principal
- Sélectionnez votre modèle dans la liste des modèles téléchargés
- Cliquez sur "Load Model" et attendez le chargement
- Ajustez les paramètres si nécessaire (température, longueur maximale)
- Tapez votre première question et appuyez sur Entrée !
Votre IA personnelle est maintenant opérationnelle. La première réponse peut prendre quelques secondes, les suivantes seront plus rapides.
Alternative avancée : Ollama pour les utilisateurs experts
Pour ceux qui recherchent plus de flexibilité, Ollama représente une excellente alternative à LM Studio. Cet outil open source privilégie les performances et l'intégration.
Installation d'Ollama (5 minutes)
Sur Windows :
- Téléchargez l'installateur sur ollama.ai
- Exécutez-le en tant qu'administrateur
- Ouvrez PowerShell ou l'invite de commandes
- Testez avec ollama --version
Sur macOS/Linux :
bash
curl -fsSL https://ollama.ai/install.sh | sh
Sur macOS avec Homebrew :
bash
brew install ollama
Utilisation d'Ollama
1. Installer un modèle :
bash
ollama pull mistral
2. Lancer une conversation :
bash
ollama run mistral
3. Utiliser l'API :
bash
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Explique-moi l'IA en termes simples"
}'
Ollama offre des performances généralement supérieures à LM Studio, notamment en vitesse d'inférence, mais nécessite plus de compétences techniques.
Comparatif détaillé : LM Studio vs Ollama
Interface et facilité d'utilisation
LM Studio brille par son interface graphique intuitive. Parfait pour les débutants, il propose une expérience "point-and-click" similaire aux applications classiques. L'exploration des modèles, les téléchargements et la configuration se font visuellement.
Ollama mise sur la simplicité de la ligne de commande. Bien que moins accessible aux novices, il offre une puissance et une flexibilité inégalées pour les développeurs. L'automatisation et l'intégration dans des scripts deviennent triviales.
Performances et optimisation
Les tests révèlent qu'Ollama est généralement plus rapide que LM Studio, particulièrement sur les modèles de grande taille. Sa gestion optimisée de la mémoire permet de faire tourner des modèles plus volumineux sur le même matériel.
LM Studio compense par une meilleure stabilité et une gestion des erreurs plus conviviale. Les débutants apprécient ses messages d'erreur explicites et ses suggestions automatiques.
Écosystème et extensibilité
Ollama dispose d'un écosystème riche avec de nombreuses interfaces tiers (Open WebUI, AnythingLLM, etc.) et s'intègre parfaitement dans les workflows de développement via son API REST native.
LM Studio privilégie l'expérience utilisateur intégrée avec ses fonctionnalités RAG (Retrieval Augmented Generation) et son serveur local optionnel compatible OpenAI.
Optimisation des performances et troubleshooting
Améliorer les performances
Gestion de la mémoire :
- Fermez les applications gourmandes avant de lancer votre LLM
- Augmentez la mémoire virtuelle si nécessaire
- Surveillez l'utilisation RAM avec le gestionnaire des tâches
Optimisation GPU :
- Mettez à jour vos pilotes NVIDIA/AMD
- Activez l'accélération matérielle dans les paramètres
- Vérifiez que CUDA est bien installé (NVIDIA)
Paramétrage du modèle :
- Réduisez la longueur maximale de contexte si nécessaire
- Ajustez la température (plus basse = plus précis, plus haute = plus créatif)
- Utilisez des versions quantifiées (Q4, Q5) pour économiser la mémoire
Résolution des problèmes courants
Le modèle ne se charge pas :
- Vérifiez l'espace disque disponible
- Redémarrez l'application
- Essayez un modèle plus léger
- Vérifiez les permissions de fichiers
Réponses trop lentes :
- Passez à un modèle plus petit
- Activez l'accélération GPU
- Fermez les applications en arrière-plan
- Réduisez les paramètres de qualité
Plantages fréquents :
- Diminuez la taille du contexte
- Vérifiez la température du processeur/GPU
- Mettez à jour l'application
- Testez avec un autre modèle
Cas d'usage avancés et intégrations
Assistant de développement
Configurez DeepSeek Coder ou Code Llama comme assistant de programmation. Ces modèles spécialisés peuvent :
- Générer du code dans 50+ langages
- Déboguer et optimiser vos scripts
- Expliquer du code complexe
- Suggérer des améliorations architecturales
Traitement de documents
Utilisez l'intégration RAG pour analyser vos documents privés :
- Extraction d'informations depuis des PDFs
- Résumés automatiques de rapports
- Questions-réponses sur des bases documentaires
- Traduction de contenus sensibles
Automatisation avec n8n/Make
Connectez votre LLM local aux plateformes d'automatisation :
- Traitement automatique de courriels
- Génération de contenus pour réseaux sociaux
- Analyse de sentiments sur des données clients
- Création de rapports automatisés
L'avenir des LLM locaux et tendances 2025
L'année 2025 marque un tournant décisif pour les LLM locaux. Les modèles deviennent plus efficaces tout en conservant leurs performances. Les nouvelles architectures comme les Mixture of Experts (MoE) permettent d'obtenir des capacités de modèles 70B avec les ressources d'un modèle 7B.
L'intégration multimodale se généralise : les prochains modèles locaux traiteront nativement texte, images, audio et vidéo. Cette convergence transformera nos ordinateurs personnels en centres de traitement IA universels.
La démocratisation s'accélère grâce à des outils toujours plus intuitifs. Les prochaines générations de LM Studio et Ollama promettent une installation en un clic et une configuration automatique selon votre matériel.
Sécurité et bonnes pratiques
Protection de vos données
Même en local, adoptez de bonnes pratiques :
- Chiffrez votre disque dur (BitLocker/FileVault)
- Sauvegardez vos modèles personnalisés
- Limitez l'accès réseau si non nécessaire
- Mettez à jour régulièrement vos outils
Utilisation responsable
Respectez les licences des modèles utilisés. Certains interdisent l'usage commercial ou imposent des restrictions spécifiques. Consultez toujours la documentation officielle avant un déploiement professionnel.
Performance énergétique
Les LLM consomment beaucoup d'énergie. Configurez votre système pour :
- Utiliser le mode économie quand possible
- Limiter la fréquence GPU en utilisation normale
- Programmer des arrêts automatiques
- Surveiller la température des composants
Votre IA personnelle vous attend
Installer un LLM sur votre ordinateur n'a jamais été aussi simple et accessible. Que vous choisissiez LM Studio pour sa simplicité ou Ollama pour sa puissance, vous disposez maintenant de tous les outils pour créer votre assistant IA personnel.
Les avantages sont considérables : confidentialité totale, disponibilité permanente, personnalisation poussée et économies substantielles à long terme. Les quelques contraintes matérielles sont largement compensées par l'indépendance et la liberté offertes.
N'hésitez plus : téléchargez LM Studio dès aujourd'hui, installez Mistral Small 3, et découvrez la révolution de l'IA personnelle. Votre assistant numérique privé vous attend, prêt à transformer votre façon de travailler et de créer.
L'intelligence artificielle démocratisée, c'est maintenant !